1. Funkcje strzałkowe
Pierwszą rzeczą, którą opiszę, są funkcje strzałkowe, które na dobre zadomowiły się w nowoczesnym kodzie pisanym przez programistów JS.
Zostały one po raz pierwszy przedstawione w ramach wydania ECMAScript 2015, znanym również jako ES6. Ich twórcy inspirowali się innymi językami programowania, w których funkcjonują tzw. wyrażenia lambda - to inaczej funkcje anonimowe, czyli takie, które nie muszą mieć przypisanej konkretnej nazwy i mogą być definiowane w imejscu, gdzie są potrzebne, np. jako argumenty funkcji. Cechują je zwięzłość, funkcjonalność i dobre współgranie z innymi konstrukcjami języka.
// Definiujemy tablicę liczb w jednej zmiennej, a w drugiej - mapujemy, mnożąc wartość każdej liczby przez 2
// Stary sposób:
const numbers = [1, 2, 3];
const doubled = numbers.map(function(n) {
return n * 2;
});
// Obecny sposób:
const numbers = [1, 2, 3];
const doubled = numbers.map(n => n * 2);Jak widzimy - dzięki funkcjom strzałkowym unikamy używania zbędnych słów kluczowych, deklarowania całych bloków kodu w celu wykonania prostych czynności i sprawiamy, że nasze oczy i mózg są w stanie o wiele szybciej odczytać intencję płynącą z kodu.
Należy pamiętać, że choć funkcje strzałkowe są inspirowane lambdami, nie są one dokładnie tym samym, a raczej ich mocno uproszczoną implementacją.
Funkcje strzałkowe pod maską
Funkcje strzałkowe nie tworzą własnego kontekstu wykonywania - działa on inaczej niż w przypadku zwykłych funkcji. Jest on determinowany w momencie definiowania funkcji, a nie wykonywania - pozostanie on niezmienny niezależnie od tego, w jakim miejscu wywołamy taką funkcję. To zjawisko nazywamy "leksykalnym wiązaniem this". Tradycyjnie, this w zwyczajnych funkcjach jest dynamiczne i zależy od kontekstu wykonywania.
Tam, gdzie ES6 nie jest obsługiwany, możemy skorzystać z transpilacji, czyli przekształcenia kodu JS z nowszego standardu na taki zgodny ze starszym, na przykład ES5. Funkcje strzałkowe przekształcane są w zwykłe funkcje z zachowaniem odpowiedniego kontekstu. Odbywa się to przez zapisanie wartości prawdziwego this do zmiennej, której nazwa jest następnie podmieniana tam, gdzie funkcja strzałkowa próbuje używać słówka this. Przykład:
// Kod ES6 i nowsze:
class Example {
constructor() {
this.value = 5;
this.getValue = () => this.value;
}
}
// ----------
// Po transpilacji do ES5:
function Example() {
var _this = this; // tworzenie zmiennej, zawierającej this
this.value = 5;
this.getValue = function() {
return _this.value;
}
}Tak przetranspilowany kod trafia do naszego javascriptowego kodu wysyłanego i uruchamianego w przeglądarce użytkownika - dzięki temu nawet starsze oprogramowanie, które nie obsługuje najnowszych standardów, może w pełni korzystać z naszej strony lub aplikacji.
Brak własnych argumentów
Funkcje strzałkowe pozbawione są również własnej tablicy arguments. W "zwykłych" funkcjach korzystamy z tego dobrodziejstwa jako z dynamicznie deklarowanej listy argumentów nawet w tych funkcjach, w której argumenty nie zostały z góry zadeklarowane.
arguments w przypadku funkcji strzałkowych zostanie potraktowane jako najzwyczajniejsza zmienna, której należy szukać w aktualnym zakresie, a której nie ma dostępnej domyślnie w ramach tej funkcji.
function normalFn() {
console.log(arguments);
}
normalFn(1, 2, 3, 4); // rezultat: [1, 2, 3, 4]
const arrowFn = () => {
console.log(arguments);
}
arrowFn(1, 2, 3, 4); // rezultat: błąd, arguments is not definedZwracanie obiektów z funkcji strzałkowych
Chcąc zwrócić nowy obiekt za pomocą funkcji strzałkowej, intuicyjnie moglibyśmy popełnić coś takiego:
const createObj = (values) => {
...values,
param: 5,
};Jednak nie będzie to prawidłowa składnia. Otwarcie nawiasów klamrowych zaraz za strzałką oznacza w JS otwarcie nowego bloku kodu, gdzie kompilator będzie spodziewał się zastać kod do wykonania, a nie tylko obiekt do zwrócenia. Aby móc zwrócić nowy obiekt z funkcji strzałkowej, tak, jak możemy zwrócić dowolną inną wartość, musimy otoczyć obiekt nawiasem okrągłym:
const createObj = (values) => ({
...values,
param: 5,
});Tak przygotowany i zwrócony obiekt jest od razu gotowy do podania na stół. 😜
Inne ograniczenia
Opisywane dotąd funkcje strzałkowe mają również parę innych ograniczeń - nie można z nich korzystać jako z konstruktorów obiektów, jak ma to miejsce w przypadku tradycyjnych funkcji, a zatem nie można ich wywoływać ze słówkiem kluczowym new oraz korzystać w nich z funkcji super(), ani właściwości new.target. Te ograniczenia również wynikają z faktu, że funkcje strzałkowe nie tworzą kontekstu wykonywania.
2. Szablony literałowe (template literals)
Template literals również zostały wprowadzone do języka JS przy okazji standardu ES6, podobnie jak funkcje strzałkowe. Pozwalają one na tworzenie łańcuchów znaków (strings) w sposób, który wcześniej nie był w ogóle dostępny.
Wielowierszowość
Szablony literałowe można całkowicie intuicyjnie deklarować w wielu wierszach. Wcześniej musieliśmy używać w tym celu tzw. znaku ucieczki (escape character), w wielu językach programowania reprezentowanego przez "\n" - to powodowało, że kod deklarujący tekst był o wiele mniej czytelny.
// Kod ES6 i nowsze:
const text = `Lorem ipsum dolor sit amet.
Consectetur adipiscing elit`;
// Po transpilacji to ES5:
var text = "Lorem ipsum dolor sit amet.\n\nConsectetur adipiscing elit";Interpolacja wartości
Dzięki użyciu znaku dolara i nawiasów klamrowych, możemy w ramach szablonów dokonywać tzw. interpolacji wartości. Ta technika polega dosłownie na dynamicznym podstawianiu wartości zmiennych lub wyrażeń bezpośrednio do łańcucha znaków, który określamy w kodzie.
Elementy interpolacji mogą zawierać dowolny, prawidłowy kod JavaScript, który zwraca jakąś wartość - to oznacza, że jeśli zechcemy, możemy podstawiać w nich zmienne, działania matematyczne, czy nawet deklarować i wykonywać funkcje, pod warunkiem, że na końcu zwrócimy prawidłowy typ prosty, który zostanie przekonwertowany na string - aczkolwiek zalecam trzymanie się możliwie jak najprostszych wyrażeń i unikanie interpolowania rozbudowanego kodu, a to z powodu czytelności.
Kod korzystający z interpolacji jest w trakcie transpilacji zamieniany na kontatenację stringów, czyli zwyczajne dodawanie do siebie łańcuchów znaków i wyrażeń.
// Kod ES6 i nowsze
const name = "Patryk";
const text = `Witaj, ${name}!`;
// ----------
// Po transpilacji do ES5:
var name = "Patryk";
var text = "Witaj, " + name + "!";
// ----------
// Wynik w obu przypadkach: "Witaj, Patryk!"Tagowanie literałów szablonowych
Choć nazwa brzmi bardzo tajemniczo, nie ma tutaj wielkiej filozofii. Przez tagowanie rozumiemy po prostu używanie funkcji, zadeklarowanych w konkretny sposób i zwracające konkretny typ danych (w tym przypadku ciągi znaków) i przyjmująca: a) szablon literałowy oraz b) opcjonalnie, tablicę interpolowanych wartości. Dzięki tym funkcjom możemy łatwo przetwarzać tekst w podanych szablonów literałowych przy użyciu specjalnej składni, która nie wymaga użycia nawiasów okrągłych do wywołania tych funkcji.
Każda interpolowana wartość jest w takiej funkcji traktowana jako element tablicy w drugim podanym argumencie funkcji. W ten sposób możemy osobno przetwarzać interpolowane dane, jeśli mamy taką potrzebę.
Z rozwiązania tego korzystają m. in. popularne biblioteki do stylowania komponentów w React, takie jak styled-components czy emotion.
// Funkcja, która pokoloruje tekst wyświelany w logu na zielono
function green(strings) {
return `\x1b[32m${strings[0]}\x1b[0m`;
}
// Wyświetlamy loga z dwoma ciągami znaków - jeden przetworzony przez funkcję `green`, drugi nie:
console.log(green`Sukces!`, "Udało się pomyślnie wykonać akcję!");Rezultat:
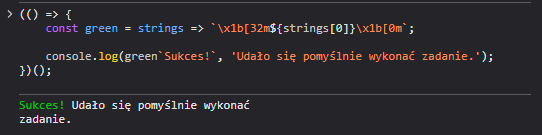
W wyniku transpilacji do ES5, kod zawierający tagowane szablony literałowe zostaje zamieniany na dwie "zwykłe" funkcje, które przetwarzają podany string wraz z interpolowanymi właściwościami, które się w nim znajdą. Dodatkowo, tworzona jest zmienna, służąca jako cache dla przetworzonych literałów szablonowych.
// Cache (pamięć podręczna) dla naszego szablonu tekstu
// Jest w niej przechowywany przetworzony szablon, żeby nie tworzyć go za każdym razem.
var templateCache;
// Funkcja pomocnicza, która przetwarza nasz szablon tekstu.
function prepareTemplate(textArray, rawArray) {
// Jeśli nie podano drugiej tablicy (raw), skopiuj pierwszą
if (!rawArray) {
rawArray = textArray.slice(0);
}
// Zamrażamy przed zmianami obiekt z naszym tekstem. Od tej pory JS nie będzie mógł zmienić wartości istniejących pól.
// Dodajemy do niego specjalną właściwość 'raw', zawierającą przetworzone znaki w formie tekstu
return Object.freeze(
Object.defineProperties(
textArray,
{
raw: {
value: Object.freeze(rawArray),
}
}
)
);
}Pierwsza funkcja przyjmuje jako argumenty tablicę stringów oraz opcjonalną tablicę "surowych" stringów. Ta funkcja to dokładna implementacja standardu wprowadzonego do ES6.
Druga funkcja to już przetranspilowana wersja naszej funkcji, która koloruje tekst w konsoli na zielono. Zostaje ona przetworzona na najzwyczajniejszą funkcję, która konkatenuje wartości:
function green(strings) {
var greenColorCode = "\x1B[32m";var resetColorCode = "\x1B[0m";// Bierzemy pierwszy element z tablicy strings i konkatenujemy dla niego stringi kolorujące tekst w konsoli:var output = greenColorCode + strings[0] + resetColorCode; // Zwracamy przetworzony string: return output; }Następnie, wywołania naszych template stringów z funkcjami tagującymi zostają zamienione na wywołania z użyciem zmiennej zawierającej cache:
console.log(
green(
temlateCache || (templateCache = prepareTemplate(["Sukces!"])
)
);Dokładne działanie biblioteki Babel, która jest najpopularniejszym wyborem, jeśli chodzi o transpilację kodu JavaScript do starszych wersji, możecie zobaczyć (i pozmieniać) na stronie babeljs.io.
3. Destrukturyzacja
Destrukturyzacji możemy używać na dwóch strukturach danych: obiektach i tablicach. Pozwala ona na wyciągnięcie właściwości obiektów lub elementów tablic do zmiennych - w przypadku obiektów będą to zmienne o takich samych nazwach, jak właściwości, które wyciągamy (choć możemy je od razu zmapować), natomiast w przypadku tablic możemy je nazywać dowolnie, ale musimy pamiętać tym, aby przypisać odpowiednie nazwy do konkretnych indeksów tablicy.
Przykłady:
// Destrukturyzacja obiektu
const obj = { val1: 5, val2: 10 };
const { val1, val2 } = obj; // w tym momencie powstają dwie zmienne o nazwach val1 i val2
console.log(val1, val2); // rezultat: 5, 10
// Destrukturyzacja tablicy
const arr = [1, 2, 3, 'elem'];
const [elem1, elem2, elem3, elem4] = arr; // w tym momencie powstają 4 zmienne o nazwach elem1...elem4
console.log(elem1, elem2, elem3, elem4); // rezultat: 1, 2, 3, 'elem'Destrukturyzacja pod maską
W celu wykonania destrukturyzacji, język JavaScript wykonuje całą serię operacji, aby przepisać wartości do odpowiednich zmiennych.
Sprawdza, czy obiekt po prawej stronie jest obiektem lub tablicą.
Próbuje znaleźć właściwości o nazwach zgodnych z kluczami obiektu po lewej stronie, lub odpowiednich indeksów tablicy.
Przypisuje wartości znalezionych właściwości lub indeksów do nowej zmiennej.
Transpilatory, takie jak Babel, zamienią kod z destrukturyzacją na tradycyjne przypisania, aby kod był zgodny ze starszymi wersjami JavaScript.
// Przetranspilowany kod
const arr = [1, 2, 3, 'elem'];
const elem1 = arr[0];
const elem2 = arr[1];
const elem3 = arr[2];
const elem4 = arr[3];Destrukturyzacja z wartościami domyślnymi
Jeśli mamy obiekt lub tablicę, wobec której nie mamy pewności, czy konkretne jej właściwości lub elementy w ogóle istnieją, możemy skorzystać z opcji przypisania domyślnych wartości przy destrukturyzacji.
// Obiekty
const obj = { a: 'a', b: 'b' };
const { a = '1', b = '2', c = '3' };
console.log(a, b, c); // rezultat: 'a', 'b', 3
// Tablica
const arr = [1, 2];
const [a = 'a', b = 'b', c = 'c'] = arr;
console.log(a, b, c); // rezultat: 1, 2, 'c'W obu powyższych przykładach deklarujemy obiekt i tablicę o dwóch elementach. Poniżej nich, próbujemy dokonać destrukturyzacji z nich trzech elementów, ale z użyciem domyślnych wartości - dzięki czemu z tablicy i obiektu pomyślnie przypisujemy do nowych zmiennych wartości z nich wyciągnięte, natomiast w przypadku trzeciego elementu zostaje przypisana wartość domyślna - bo nie istnieje ona w destrukturyzowanym przedmiocie.
Destrukturyzacja zagnieżdżonych obiektów i tablic
Dokładnie tak samo, jak możemy zagnieżdżać obiekty i tablice wewnątrz innych obiektów i tablic, tak możemy je destrukturyzować. W takich przypadkach składnia jest intuicyjna i spójna.
// Obiekty
const obj = {
a: 'a',
obj2: {
b: 'b',
c: 'c',
}
};
const { a, obj2: { b, c } } = obj; // w tym miejscu powstają trzy zmienne a, b oraz c
console.log(a, b, c); // rezultat: 'a', 'b', 'c'
// Tablice
const arr = [1, 2, [3, 4]];
const [a, b, [c, d]] = arr; // w tym miejscu powstają cztery zmienne a, b, c oraz d
console.log(a, b, c, d); // rezultat: 1, 2, 3, 4Destrukturyzacja zagnieżdżonych danych jest szczególnie przydatna przy pracy z mocno zagnieżdżonymi obiektami - na przykład z odpowiedziami z API, gdzie mamy bardzo rozbudowane informacje: na przykład listę użytkowników,
Destrukturyzacja parametrów funkcji
Przyjmując parametry wewnątrz deklaracji funkcji, możemy od razu dokonywać destrukturyzacji potrzebnych elementów i przetwarzać je na zmienne działające wewnątrz zakresu leksykalnego tej funkcji.
function add([a, b, c]) {
return a + b + c;
}
const nums = [1, 2, 3];
console.log(add(nums)); // rezultat: 6Jak widzimy, destrukturyzacja pozwala nam uczynić kod bardzo zwięzłym i prostym, a w dodatku o wiele bardziej czytelnym przez brak potrzeby wywoływania się wciąż do tego samego obiektu lub tablicy, a zamiast tego możemy uzyskać łatwy dostęp do jego właściwości za pomocą pojedynczych zmiennych w jednym miejscu.
4. async/await
Niniejszy mechanizm jest prawdopobonie największy i najbardziej rewolucyjny spośród tych opisanych tutaj, wprowadzonych w ostatnich latach w języku JavaScript. Praca z operacjami asynchronicznymi zawsze sprawiała trochę kłopotu, zwłaszcza, jeśli te operacje są skomplikowane, zawiłe i zależą od siebie nawzajem.
Promise
W ES6, tym samym standardzie, który dał nam m. in. funkcje strzałkowe, pojawiły się tzw Obietnice (ang. Promise). Promise były nowym typem obiektów, które reprezentują wyniki operacji asynchronicznych, które w momencie wywołania mogą byc jeszcze niezakończone, ale stanowią obietnicę, że zostaną one zakończone (powodzeniem lub błędem) w przyszłości.
Miały one zastąpić na dobre callbacki, czyli dotychczasową metodę zagnieżdżania w sobie wielu funkcji, przekazywanych pomiędzy nimi jako argumenty, które są wykonywane po zakończeniu jakiejś operacji - asynchronicznej lub synchronicznej. Typowym przykładem jest uruchamianie tzw. timeoutów. Wbudowana w JS funkcja setTimeout przyjmuje jako pierwszy argument funkcję, która zostanie wykonana po odliczeniu żądanego czasu.
setTimeout(
// funkcja wywoływana asynchronicznie po zakończeniu odliczania - callback
() => {
console.log('Ten log pojawi się w konsoli po 3 sekundach!');
},
// czas odliczania w milisekundach do wywołania callbacka
3000
);Dzięki Promise, możemy taki callback zastąpić funkcją, która zwróci Promise, a ten w swojej implementacji użyje funkcji setTimeout do wywołania konkretnego kodu po upłynięciu żądanego czasu:
function wait() {
return new Promise((resolve) => {
// "resolve" jako callback pomyślnie zakańcza działanie Promise po upłynięciu 3 sekund
setTimeout(resolve, 3000);
});
}
wait()
.then(() => {
// Promise pomyślnie wykonany po upłynięciu 3 sekund
console.log('Ten log pojawi się w konsoli po 3 sekundach!');
})
.catch((err) => {
// w przypadku wystąpienia błędu - tutaj możemy go obsłużyć
console.error('Wystąpił błąd. ', err);
});async/await jako syntactic sugar dla Promise
Mechanizm `async/await` opiera się w całości o pracy na Promisach - jednak mocno ukrywa ich złożoność, pozwalając nam pisać kod asynchroniczny w taki sposób, jak gdyby był on synchroniczny.
Słowo kluczowe async przed funkcją oznacza, że z założenia ma ona zwrócić nam Promise. Nawet, jeśli zwrócimy wartość synchroniczną - na przykład liczbę 5 - zostanie ona automatycznie opakowana w obiekt Promise.
const getFive = async () => {
return 5;
}
// getFive() zwraca obiekt Promise, a nie 5!
const value = getFive();
console.log(value); // rezultat: Promise { <fulfilled>: 5 }W celu wyciągnięcia "prawdziwej" wartości z funkcji asynchronicznej, musimy użyć kolejnego słowa kluczowego await. Uwaga - możemy to zrobić tylko i wyłącznie wewnątrz innej funkcji asynchronicznej, która również zwróci Promise.
const getFive = async () => 5;
const run = async () => {
const value = await getFive();
console.log('Mam piątkę! ' + value); // rezultat: "Mam piątkę! 5"
};
run();Mimo, że funkcja `run` jest asynchroniczna i zwraca Promise - nie oczekujemy od niej żadnej wartości, którą potrzebowalibyśmy wyciągnąć. Chcemy tylko, by została uruchomiona, i tak się stanie. Powyższy kod poprawnie wykona treść funkcji i wyświetli w konsoli odpowiedni log, z poprawnie oczekiwaną cyfrą 5.
Obsługa błędów w async/await
Błędy obsługiwane w ramach operacji z async/await również zostały dobrze przemyślane. Blok try..catch w JS potafi wychwytywać Promise, które się nie powiodły, lub w których został rzucony błąd.
Posłużmy się ponownie przykładem z wyciąganiem piątki z funkcji asynchronicznej, tym razem rzucając błąd przez zwróceniem wartości.
const getFive = async () => {
throw new Error('Błąd!');
return 5;
};
const run = async () => {
try {
const value = await getFive();
console.log('Mam piątkę! ' + value);
} catch (error) {
console.error('Błąd funkcji asynchronicznej!');
}
};
run();Tym razem, w konsoli nie zobaczymy komunikatu z cyfrą, jak w przypadku poprzedniego kodu, za to zobaczymy informację o błędzie:
Error: Błąd funkcji asynchronicznej! at run (<anonymous>:2:15) at async <anonymous>:13:9
async/await pod maską
Pod spodem, JS transformuje każde użycie async/await na zwykłe Promise oraz generatory. Funkcje deklarowane z przedrostkiem async przekształcane są na takie, które bezpośrednio zwracają obiekt Promise, a każde użycie await tłumaczone jest na łańcuch z .then().
5. Pozostałe syntactic sugar w JS
JS jest pełen innych, mniejszych, choć nie mniej ważnych syntactic sugar, które mogą okazać się pomocne w codziennym pisaniu kodu. Poniżej opiszę je bardzo pokrótce.
Nullish Coalescing Operator
Operator ??, który zwróci wartość po prawej stronie, jeśli ta po lewej jest null albo undefined:
const value = null;
const result = value ?? 'Coś innego';
console.log(result); // rezultat: "Coś innego"Optional Chaining Operator
Operator ?., który pozwala na bezpieczne wywoływanie konkretnej właściwości obiektu lub jego funkcji, nawet, jeśli nie istnieją. Jeśli spróbujemy odwołać się do czegoś, co po kropce normalnie rzuciłoby błąd mówiący o tym, że chcemy wywołać coś, co nie istnieje, zamiast błędu całe wyrażenie zwróci po prostu wartość undefined.
address: {
name: 'Long Street',
};
console.log(user.address?.name); // rezultat: "Long Street"
console.log(user.address?.number); // rezultat: undefinedSkładnia klas
Jako, że JS jest językiem prototypowym, nie istnieją w nim klasy w tradycyjnym sensie - zamiast tego w języku funkcjonują tzw. prototypy. Klasy definiowane przez nas słówkiem kluczowym class tłumaczone są pod maską właśnie na prototypy - ale możemy je opisywać podobnie, jak w każdym innym języku obiektowym, opartym o klasy.
class User {
constructor(name) {
this.name = name;
}
getName() {
return this.name;
}
}
const patryk = new User("Patryk");
console.log(patryk.getName()); // rezultat: "Patryk"Operatory Spread i Rest
Spread operator ułatwia tworzenie nowych obiektów i tablic, będących rozszerzeniami dla już istniejących. Nowa tablica lub obiekt będą zawierały wszystkie dotychczasowe elementy tablicy lub obiektu, który "rozprzestrzeniamy" w innym:
const numbers = [1, 2, 3];
const newNumbers = [...numbers, 4, 5, 6]; // rezultat: [1, 2, 3, 4, 5, 6];Natomiast rest operator pozwala na przechwytywanie pozostałych argumentów funkcji, jako zmienną zawierającą pojedynczą tablicę:
const restFn = (...numbers) => {
// wypisz w logu wszystkie numery, podane jako osobne argumenty funkcji
console.log(numbers);
}
restFn(1, 2, 3, 4, 5); // rezultat: [1, 2, 3, 4, 5];Składnia for..of i for..in
Ostatnim syntactic sugar opisanym tutaj będzie for..of, czyli łatwiejsze iterowanie po elementach tablic, oraz bezpośrednio po ich wartościach.
for..in pozwala iterować po indeksach:
const arr = ['a', 'b', 'c'];
for (const index in arr) {
// w zmiennej `index` jest aktualny indeks tablicy, po której iterujemy
console.log(index, arr[index]);
}
// rezultat:
// 0, "a"
// 1, "b"
// 2, "c"Natomiast for..of iteruje bezpośrednio po wartościach:
const arr = ['a', 'b', 'c'];
for (const value of arr) {
console.log(value);
}
// rezultat:
// "a"
// "b"
// "c"Podsumowanie
W tym wpisie starałem się jak najbardziej szczegółowo opisać najważniejsze syntactic sugar w języku JavaScript i przedstawić przykłady, które wyjaśnią mechanizmy działania kodu w takiej uproszczonej składni. Mam nadzieję, że pomoże on zrozumieć, w jaki sposób działają te ułatwienia oraz jak wykorzystywać je w codziennym programowaniu, aby pracować efektywnie i tworzyć czytelny kod.